自然言語処理や AI 技術について
こんにちは。プロアクシアコンサルティングでオープンソリューション第1事業部に所属しています S.M です。
オープンソリューションのシステム開発及び実装をメインで担当しています。
本日は自然言語処理や AI 技術についてご紹介したいと思います。
プロアクシアでの役割とこれまでの経験を教えてください
学生時代は、ゲーム理論など、ゲームを作るための知識を学ぶ学科に在籍していて、卒業研究ではスマートフォンが Wi-Fi を利用する際に発する電波を追跡することによって人流解析ができないかなどを研究していました。
卒業後も IT 関連の研究開発に携わる仕事に就きたいと考えていたところ、教授から紹介いただいたプロアクシアコンサルティングが携わっている音声翻訳プロジェクトに興味を持ったのがきっかけで 2014 年に新卒入社しました。
現在の役割としては、C 言語や Python を利用したオープン系の開発業務を経て、現在は研究所での研究開発補助の案件に携わっております。
オープンソリューションでは、どのような技術分野やソリューションを担当しましたか
全般的に音声関係のプロジェクトを中心に担当をしており、音声翻訳エンジンを Linux / Windows から利用するための SDK の開発や、ディープラーニングを使った研究開発の補助、英語の定型発音評価システムのエンジン開発などの開発業務を担当しております。

研究開発では音声から少し離れ、機械翻訳における固有名詞の翻訳の困難さに着眼し、そこでの翻訳精度の改善に向けた研究の補助や、記述式のテストを模範解答と生徒さんの回答の類似度を推定することによって自動採点を行なうための AI の学習などを担当しています。
自然言語処理や機械学習とのかかわりは、どのようなきっかけですか
学生時代から、自然言語処理に興味は持っておりましたが、研究などのかかわりは持っておりませんでした。
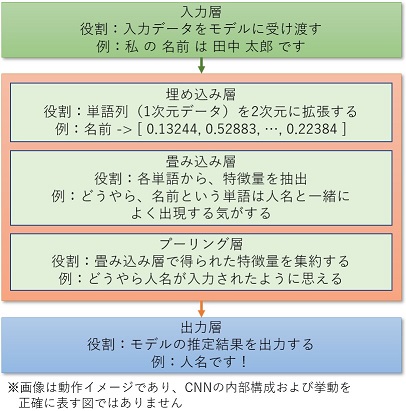
機械学習の代表格であるディープラーニングとのかかわりは、2017年に CNN (Convolutional neural network) を利用した文書分類の案件を担当した際が初めてです。ちなみにこの文書分類は、現在まで続いている固有名詞の翻訳精度改善に関連しています。
当時文書分類の機械学習モデルとしては LSTM (Long Short Term Memory) という、時系列データの入力を前提としたモデル構造が主流だったのですが、お客様から CNN による文書分類の論文とサンプルコードをいただき、見様見真似で動作させました。
当時の機械学習のサンプルコードは、現在ほどモデル構造の数式がライブラリ内部に隠蔽されていませんでした。そのため読解やお客様が所有されているデータへの適用に苦労した記憶がありますが、その分うまく動いた時は嬉しかったです。
プロアクシアコンサルティングでは自然言語処理や AI 技術をどのように利用されていますか
英語の定形発音評価、テキストのカテゴリ分類、機械翻訳などのサービスを提供するために、自然言語処理や AI の技術を利用しております。
英語の定形発音評価では、英語を学習されている方の発声内容を、音声認識技術と信号処理技術をベースに、ネイティブの発音や発声と比較する機能を開発しています。単純に AI で比較するだけでなく、日本人の特性に合わせた評価ができるように AI に学習させました。
これを利用することで、評価者による評価の偏りを少なくし、明示された評価基準によってより細かな評価をすることができるようになります。
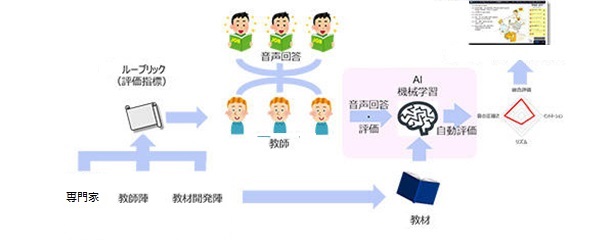
データヘルスの分野での利用では、Web 会議ツールと連携した自動問診システムの開発にも利用されています。
患者からの音声での回答内容を認識するだけでなく、音声の抑揚やアクセントなどから感情推定を行い、回答内容に含まれるより多くの情報を引き出せるようにするための部分を AI を利用して開発を行いました。
お客様ニーズを満たすためにどのようなアプローチを行いますか
特に研究開発支援では、最終的に出来上がるのはプロダクトではなく、実験の精度となります。
そのため、「実験の結果、精度は○○%でした」のような簡単な報告でタスクが完了したような気持ちになってしまうことがあります。
ですが、最終結果の精度だけを報告するのではなく、入力データや中間結果、モデルの推定値なども含めた、詳細な報告を心がけています。そうすることによって、お客様にとっても自分にとっても、データや実装の不備に気づきやすい、内部挙動の考察につながるなどのメリットがあると感じています。
お客様にとってプロアクシアに任せていただくことのメリットは何でしょうか
私は、AI 開発者としてまだまだ道半ばです。
ですが、だからこそ AI の導入を検討されているお客様の要望事項が困難に思えたとしても、要望を無下にすることなく、愚直な試行錯誤を厭わず、ともに実現への可能性を模索していけるものと信じております。
AI について、今興味を持っていることはなんですか
非営利団体の Open AI が研究している自然言語処理モデルの GPT-3 の AI モデルでは、インタラクティブな AI で巨大なデータセットやネットワークを利用することで、人間が書いたような自然な文章作成や画像描画、プログラムコードの作成など色々な分野での自動生成を実現できるようになってきており、大変興味をもっております。
今後の対話システムや言語処理の部分でも、 GPT-3 の AI モデルを活用すれば、今まで以上により自然な翻訳を生成できるようになるなど、人と AI とのやり取りに多いな可能性があると考えておりますので、対話システムや言語処理の部分でこれらの分野を研究していきたいと考えています。
最近はどのようなことに取り組んでいますか
プライベートでは、機械学習関連の案件に参画する中で基礎力を向上させるために、統計検定2級を取得しました。
それ以外に、データ分析および、AI開発スキルを磨きたいと考え、今は Kaggle にチャレンジ中です。
Kaggle は世界中の機械学習・データサイエンスに携わっている人が集まるコミニティーで、企業や政府がコンペ形式で課題を提示し、最も制度の高い分析モデルを競い合う取り組みが実施されています。このコンペに参加して、ブロンズメダルを取ることが現在の目標です。
チームとしての取り組みとしては、入社2,3年目の社員を技術力向上に向けて、Django と呼ばれる Web アプリケーションフレームワークの勉強会を部門内で実施しました。
この取り組みを実施することで、若手の技術力を向上させるだけでなく、勉強会のカリキュラムを作成するなどの活動を通じて自身の若手育成の知見を広めていくことができました。
今後どのような案件に携わっていきたいと考えられていますか
GPT-3 の AI モデルに興味を持っていますので、GPT-3 を活用したサービスを開発している案件に携わりたいと思っています。
まだ、GPT-3 を触ることができていないため、単なる夢物語にはなってしまうのですが、ロボットの思考エンジンにあたる部分に、GPT-3 を利用するようなことができれば面白いだろうな、と思っています。

GPT-3 の問題点として、常識を持たず、一見それらしい文章を生成するだけで、そこには論理的整合性がないことはニュースサイトで取り上げられています。そのため対策なしにブラックボックスでロボットに導入してしまえば重大な事故に繋がります。それは開発者として決してやってはいけないことです。
ですが、そういった障害を理解し対策した上で、あたかもロボットが自律的に思考しているように動かすことができれば、なかなか近未来的で面白いことになるのではないでしょうか。
GPT-3 は Open AI のサイトから試用申請ができます。つい先日、試用申請を出しました。触ってみることによって、夢が打ち砕かれるかもしれませんが、申請が通れば、色々と遊び、もう少し現実的な利用例など考えていければと思っています。
今後エンジニアとして、どのように成長していきたいとお考えですか
入社時は、自分がそもそも何をしたいのかがわからなかったため、とにかく幅広く色々な技術を知りたいと考えていました。
まだ、はっきりと「これだ!」と言えるものは見つかっていませんが、今の目標としては、人間による評価や判断が必要だが多大なコストがかかっているような作業を、AI によって幅広く自動化できるようにしていきたいと思っています。
このためには、AI に関する知見を深めるだけでなく、多くの業務に携わることで幅広くお客様に業務改善を提案できるようなエンジニアを目指していければと考えています。

